
JAVA源码解读之ConcurrentHashMap
前言
在我们日常开发中,HashMap无疑是一个被频繁使用的类,但是它本身也有自己的不足。HashMap被设计为一个线程不完全的类,这意味着它在并发读写时会有问题,所以我们日常开发时不会在并发场景使用它。而这次要分析的ConcurrentHashMap不仅具有和HashMap类似的功能,而且在并发场景下也完全没有问题。我们先看一下它的类图。
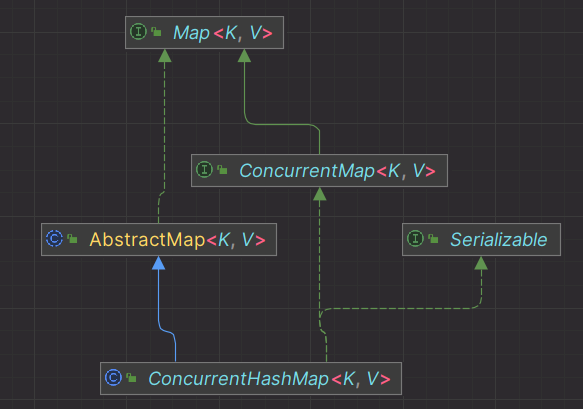
ConcurrentHashMap同时具有以下特性:
- 线程安全:ConcurrentHashMap内部使用分段锁技术,不同的线程可以同时操作不同的段,提高并发性。
- 高并发:ConcurrentHashMap允许多个线程同时读,而不需要任何锁。写操作(如put,remove等)需要锁定部分数据,而不是整个数据结构。
- 非阻塞算法:ConcurrentHashMap使用一种新的方法CAS(Compare and Swap),它是硬件对于并发操作的直接支持,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知失败,并允许再次尝试。
- 弱一致性:ConcurrentHashMap的读是弱一致的,也就是说,当你从ConcurrentHashMap中读取元素时,可能会看到其他线程插入的元素,也可能看不到。
- 支持并行操作:ConcurrentHashMap支持一系列并行操作,如mappingCount,reduce和search等。
关键属性
1 | // 最大表容量 |
构造器
1 | // 创建一个默认初始容量(16)、负载因子(0.75)和并发级别(16)的ConcurrentHashMap |
关键方法
寻址算法
给定一个key,ConcurrentHashMap是如何确定这个key应该放在哪个位置的呢?这就是寻址算法。
首先要计算这个key的hash值,在ConcurrentHashMap中它是用spread方法实现的。
1 | static final int spread(int h) { |
参数h为key的hash值,可以看到这里对hash做了二次处理,以减少哈希冲突并提高哈希表的性能。在这段代码中,先将h的高低16位进行异或处理,以减少hash冲突;然后又和HASH_BITS进行与操作,保证最后的hash值是一个正数。
计算完hash值后,我们就可以计算出这个key在数组中的索引值,算法为:(n - 1) & hash,其中n为数组的长度,即数组的长度减一后和hash值做与运算。
有索引了,如何取出索引出的数据呢?这就是tabAt()方法了
1 | static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { |
添加元素
put()
将一个键值对元素放入ConcurrentHashMap中,我们直接看底层的putVal方法,可以看到方法接受三个参数:key、value和onlyIfAbsent。key和value是要插入映射的键值对。onlyIfAbsent是一个布尔标志,表示如果映射中已存在键,是否应插入新值。
大致流程为:
- 先计算key的hash值,然后开启无限循环
- 如果此时哈希表还没初始化,则调用initTable()进行初始化
- 哈希表已初始化并且索引处的bin位空,就构造新Node插入该索引处
- 如果索引处不为空,判断节点是否为转发节点,是的话就进行调整
- 如果不是转发节点,并且onlyIfAbsent为true的话,就尝试进行值的替换而不是插入值(如果键相等的话)
- 走到这里说明索引处是一个链表或一棵树,构造节点并尝试将Node添加到链表或树中,必要时刻将链表转为树
- 累加映射中元素的计数并返回null
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
hash表的初始化过程,可以看到它使用了CAS操作和线程让步来保证在多线程环境下哈希表的正确初始化。
1 | private final Node<K,V>[] initTable() { |
addCount()
addCount()方法主要用来累计哈希表中的映射数量,并确定是否要触发扩容。简单来说,addCount()内部会尝试通过CAS的方式累加baseCount,如果累加失败就说明存在并发竞争,此时要再说在满足以下任意一个条件就要调用fullAddCount()方法:
- counterCells为null或者是空数组
- counterCells不是null或空数组,但是索引处内容为null;或者counterCells不是null或空数组,索引处也有counterCell,但是CAS累加counterCell的value值失败
完了后要进行扩容检查,我们下面会再讲扩容机制
1 | /** |
在理清addCount()方法后,我们就可以在梳理它里面的fullAddCount()方法了,它的作用就是在并发的环境下安全的累加计数值。
1 | // x 要累加的数值, wasUncontended 为true时表示上一次操作没有发生竞争 |
扩容机制
主要代码是transfer方法中,大体流程是:
首选会先计算每个线程需要处理的数量,这里是根据CPU的核心数量来计算的,如果是单核,那么每个线程处理的元素数就是原哈希表的长度;如果是多核,那么每个线程处理的元素数量为原哈希表长度的1/8;
然后再判断一下新的哈希表是否创建,未创建就创建一个大小是原哈希表两倍的新哈希表并赋值给nextTable;
接着开启一个循环,自链表尾部向前遍历依次处理哈希表中的元素;
- 循环内部会先确定当前线程处理元素的范围,主要是通过CAS设置TRANSFERINDEX来实现分段逻辑。假设现在是32扩容到64,那么会先处理的元素范围是[16,31],然后再是[0,15];
- 然后校验一下索引的有效性
- 如果索引有效,再看下当前索引处是否有元素,有的话就做迁移,迁移成功就继续下次循环;
- 如果索引处有元素,但节点的hash值是MOVE,表示已经迁移过了,跳过当前循环,继续下次循环;
- 最后说明当前节点是要被处理的,先对当前这个节点加一个独占锁,然后处理后续逻辑。这里判断了节点是否是树,树的逻辑暂不做阐述;如果是普通节点或者链表,会先构造两个链表:底链表ln和高链表hn,然后根据算法:节点的hash值和旧哈希表的长度做与运算,判断结果是否为0,为0就赋值给ln,表示它在新哈希表中的位置和旧哈希表的位置保持一致;否则就将它赋值给hn,表示它在新哈希表中的位置为它在旧哈希表的索引值+旧哈希表的长度之和。
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
访问元素
这里展示get方法,即从ConcurrentHashMap中获取key的value值。
首先会通过寻址算法找到索引处的Node,如果值为null就返回null,否则会做如下处理
- 如果Node的哈希值和key值是否和给定的key一致,一致就返回true
- 如果Node的哈希值小于0,说明这个是特殊节点,比如是一颗树或者转发节点,做特殊处理
- 否则就说明节点是一个链表,遍历这个链表,找到与给定key的哈希值和key值都相等的元素
1 | public V get(Object key) { |
移除元素
我们分析下remove方法,即从ConcurrentHashMap中移出这个key值的信息。
从第一场代码可以看出,它是调用了replaceNode(key, null, null)。
1 | public V remove(Object key) { |
1 | final V replaceNode(Object key, V value, Object cv) { |
如何计数
最后我们看下size方法,主要是调用sumCount方法。我们之前已经知道ConcurrentHashMap是将数量维护在baseCount字段和CounterCell数组中的,所以数量多计算也是baseCount的值加上所有CounterCell数组中的value值。
1 | public int size() { |
1 | final long sumCount() { |



%20(%E5%B0%8F).jpg)
.jpg)
