前言 在我们使用Spring Boot的过程中会发现Spring Boot会将启动类同级目录以及子目录下符合条件的类自动注册成Bean,比如带有@Controller,@Service等注解的类。我们今天就看下默认配置在的自动扫描是如何实现的。
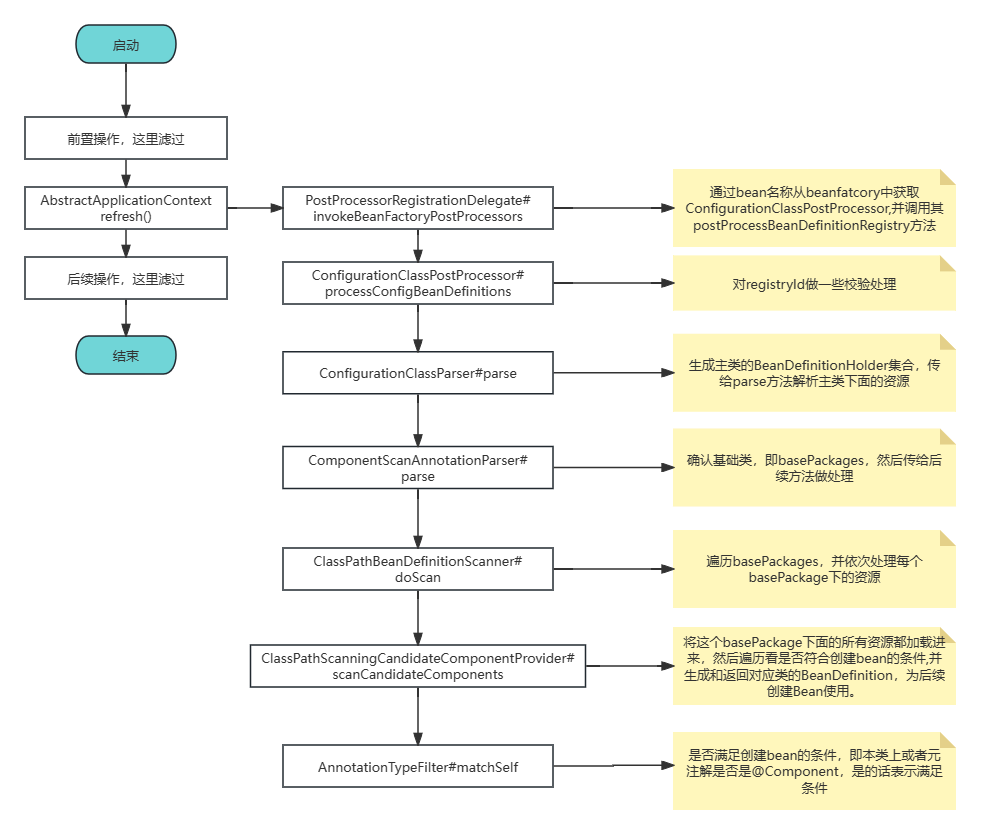
简介 Spring Boot在启动过程中会先找出一个基础类,在默认配置下就是我们启动类所在的目录,然后将这个目录下面所有的资源都加载进来,依次遍历每个资源,看他们是否符合特定条件,大体是一个正常的类,并且本类或元注解上带有@Component注解,然后创建并返回这些类的BeanDefinition,供后续创建Bean动作使用。
扫描的过程 忽略掉前置的流程,我们直接看关键部分的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private Set<BeanDefinition> scanCandidateComponents (String basePackage) { Set<BeanDefinition> candidates = new LinkedHashSet <>(); try { String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + resolveBasePackage(basePackage) + '/' + this .resourcePattern; Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath); boolean traceEnabled = logger.isTraceEnabled(); boolean debugEnabled = logger.isDebugEnabled(); for (Resource resource : resources) { String filename = resource.getFilename(); if (filename != null && filename.contains(ClassUtils.CGLIB_CLASS_SEPARATOR)) { continue ; } if (traceEnabled) { logger.trace("Scanning " + resource); } try { MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource); if (isCandidateComponent(metadataReader)) { ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition (metadataReader); sbd.setSource(resource); if (isCandidateComponent(sbd)) { if (debugEnabled) { logger.debug("Identified candidate component class: " + resource); } candidates.add(sbd); } ****************************略过无效代码**************************** return candidates; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 protected boolean isCandidateComponent (MetadataReader metadataReader) throws IOException { for (TypeFilter tf : this .excludeFilters) { if (tf.match(metadataReader, getMetadataReaderFactory())) { return false ; } } for (TypeFilter tf : this .includeFilters) { if (tf.match(metadataReader, getMetadataReaderFactory())) { return isConditionMatch(metadataReader); } } return false ; }
tf.match是判断这个资源是否匹配,内部调用的是matchSelf方法,这个方法会判断类或元注解上是否有@Component注解,满足条件返回true
1 2 3 4 5 6 7 protected boolean matchSelf (MetadataReader metadataReader) { AnnotationMetadata metadata = metadataReader.getAnnotationMetadata(); return metadata.hasAnnotation(this .annotationType.getName()) || (this .considerMetaAnnotations && metadata.hasMetaAnnotation(this .annotationType.getName())); }
总结 总的来说,自动扫描的过程可以总结如下:
启动时由invokeBeanFactoryPostProcessors方法触发
通过bean名称从beanfatcory中获取ConfigurationClassPostProcessor,并调用其postProcessBeanDefinitionRegistry方法
确认basepackages,默认机制下是启动类的包信息
遍历basepackages,获取单个basepackage下面所有的资源,遍历每个资源,然后为符合条件的资源创建BeanDefinition,这些条件为(全满足):
类上或元注解上标有@Component注解
如果类上标有@Condition条件注解,则必须要满足条件才行
类必须是独立的,比如普通的内部类是不可以的(静态内部类可以认为是独立的)
类不能是接口或抽象类,如果是抽象类,则必须带有@Lookup注解
返回包含BeanDefinition信息的Set集合






%20(%E5%B0%8F).jpg)
.jpg)