动态SQL的定义
动态 SQL 是 MyBatis 的强大特性之一。动态SQL的概念是指在MyBatis中使用条件逻辑构建的SQL语句,这些SQL语句在运行时根据传入的参数动态改变。动态SQL允许开发者在XML映射文件或使用注解的方式中,根据不同的条件组合出不同的SQL语句,从而避免了为每种可能的查询条件编写单独的SQL语句,提高了代码的复用性和灵活性。
如果一段SQL不包含动态逻辑,那么我们称它为静态SQL,比如:
1
| SELECT * FROM USER WHERE ID = #{id}
|
反之,如果一段SQL包含以下任意一个或多个元素,那么它就是动态SQL:
<if>:根据条件判断是否包含某段SQL。<choose>、<when>、<otherwise>:多分支选择,类似于Java中的switch语句。<where>:智能地插入WHERE关键字,并且能够处理其后的AND或OR关键字。<set>:智能地插入SET关键字,并且能够处理列表末尾的逗号。<foreach>:用于遍历集合,常用于构建IN条件查询。<bind>:允许创建一个变量并将其绑定到当前上下文。
动态SQL的整体流程
整体主要分为三块儿,XML、SqlSource、BoundSql,其中BoundSql就是我们的最终结果了。
在项目启动时,XML文件中的SQl脚本会被转换为SqlSource,可能是DynamicSqlSource,也可能是RawSqlSource;在服务启动后,当查询或者其它请求发过来时,Mybatis将调用DynamicSqlSource的getBoundSql()方法生成BoundSql。
.png)
SqlSource的生成过程
在生成SqlSource的过程中,重点是将原始SQL脚本的每一行语句转换为一个个的SqlNode,并将这些SqlNode收集到一个集合中,供后面生成Sql使用。
这个SqlNode的集合类似于一个树形结构,假设我们有一个动态Sql脚本如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <select id="selectUserWithIdNameAge" resultType="org.example.mybatis_reader.mybatis.UserPO">
SELECT * FROM T_USER
<where>
<if test="id != null">
AND ID = #{id}
</if>
<if test="userName != null">
AND USER_NAME = #{userName}
</if>
<if test="age != null">
AND AGE = #{age}
</if>
</where>
</select>
|
那么它的SqlNode集合就如下展示: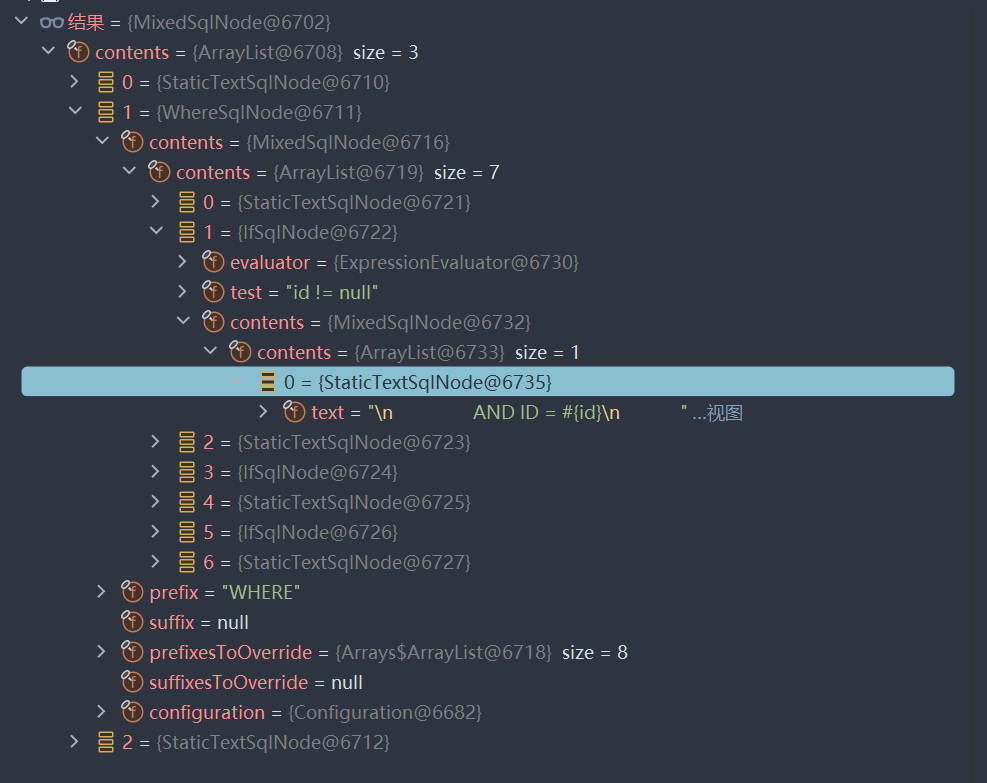
现在我们看一下源码中是如何处理这种逻辑的。源码中逻辑主要是在XMLScriptBuilder类中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public SqlSource parseScriptNode() {
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
if (isDynamic) {
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
|
我们在看下parseDynamicTags()方法的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| protected MixedSqlNode parseDynamicTags(XNode node) {
List<SqlNode> contents = new ArrayList<>();
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
isDynamic = true;
} else {
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) {
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
handler.handleNode(child, contents);
isDynamic = true;
}
}
return new MixedSqlNode(contents);
}
|
假设我们获取到的是WhereHandler,我们看下它的handleNode()方法,简单来说就是再次调用parseDynamicTags()方法,然后依据parseDynamicTags()方法的返回结构构造WhereSqlNode,并将它放入到SqlNode集合中去。
1
2
3
4
5
6
7
8
9
| @Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
WhereSqlNode where = new WhereSqlNode(configuration, mixedSqlNode);
targetContents.add(where);
}
|
BoundSql的生成过程
BoundSql是通过SqlSource来构建出来的。我们从MappedStatement类开始看起。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public BoundSql getBoundSql(Object parameterObject) {
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.isEmpty()) {
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
for (ParameterMapping pm : boundSql.getParameterMappings()) {
String rmId = pm.getResultMapId();
if (rmId != null) {
ResultMap rm = configuration.getResultMap(rmId);
if (rm != null) {
hasNestedResultMaps |= rm.hasNestedResultMaps();
}
}
}
return boundSql;
}
|
继续看DynamicSqlSource类中的getBoundSql()方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Override
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}
|
MixedSqlNode中的逻辑,主要是循环内部的contents属性,然后调用node.apply()方法去处理不同SqlNode的逻辑,比如ifSqlNode,WhereSqlNode等等。
1
2
3
4
5
| @Override
public boolean apply(DynamicContext context) {
contents.forEach(node -> node.apply(context));
return true;
}
|
我们以if语句和where语句为例,我们看下它内部的逻辑是什么。
if语句的apply()
if语句的作用是过滤掉不满足条件的语句,它是如何实现的呢?
if语句是由IfSqlNode来处理的。IfSqlNode内部有一个ExpressionEvaluator属性,而evaluator内部是基于OGNL表达式实现的,所以我们可以认为IfSqlNode的apply()方法即使通过OGNL表达式判断test是否为真,是对话就将它加入动态上下文中;否则这段语句会被过滤掉。
1
2
3
4
5
6
7
8
| @Override
public boolean apply(DynamicContext context) {
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
return false;
}
|
Where语句的apply()
标签可以自动将多余的标签删除掉,从而保证我们的SQL语法是正确的。比如前面例子中的ID前面的AND符号是被移除掉的,这又是如何实现的呢?
WhereSqlNode集成了TrimSqlNode,所以实际上调用的是TrimSqlNode中的apply()方法。WhereSqlNode中定义了一个前缀列表
1
2
| private static final List<String> prefixList = Arrays.asList("AND ", "OR ", "AND\n", "OR\n", "AND\r", "OR\r", "AND\t",
"OR\t");
|
1
2
3
4
5
6
7
8
9
10
| @Override
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
filteredDynamicContext.applyAll();
return result;
}
|
内部类FilteredDynamicContext
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
delegate.appendSql(sqlBuffer.toString());
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (prefixApplied) {
return;
}
prefixApplied = true;
if (prefixesToOverride != null) {
prefixesToOverride.stream().filter(trimmedUppercaseSql::startsWith).findFirst()
.ifPresent(toRemove -> sql.delete(0, toRemove.trim().length()));
}
if (prefix != null) {
sql.insert(0, " ").insert(0, prefix);
}
}
|




%20(%E5%B0%8F).jpg)
.jpg)




%20(%E5%B0%8F).jpg)
.jpg)