前言
我们知道,在MySQL中的关联查询语法可以使我们获得一个来源于多表的包含多个字段列表,类似这样
| id |
TITLE |
comment_id |
comment_content |
| 1 |
文章1 |
1 |
你说的对 |
| 1 |
文章1 |
2 |
写的太好了 |
前面两个字段是Blog表的字段,后面两个是评论表达字段。现在假设我们需要将这列表转换成博客对象包含评论集合的数据结构,类似这样:
1
| BlogPO(id=1, title=文章1, content=null, userId=null, comments=[CommentPO{id=1, blogId=null, userId=null, content='你说的对'}, CommentPO{id=2, blogId=null, userId=null, content='写的太好了'}])
|
当然我们完全可以用JAVA写转换逻辑,但其实Mybatis已经为我们提供了类似的功能,我们今天就看下这套机制的实现原理。
DEMO
照例还是先写一个小例子
XML的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.example.mybatis_reader.mybatis.blog.BlogMapper">
<resultMap id="BlogNestMap" type="org.example.mybatis_reader.mybatis.blog.BlogPO" autoMapping="true">
<id column="ID" property="id" jdbcType="INTEGER"/>
<result column="TITLE" property="title" jdbcType="VARCHAR"/>
<collection property="comments" ofType="org.example.mybatis_reader.mybatis.blog.CommentPO"
autoMapping="true" columnPrefix="comment_"/>
</resultMap>
<select id="selectBlogAndComment" resultType="org.example.mybatis_reader.mybatis.blog.BlogAndCommentPO">
SELECT T1.id blogId,T1.TITLE blogTitle, T2.id commentId,T2.CONTENT commentContent
FROM T_BLOG AS T1 INNER JOIN T_COMMENT T2 on T1.ID = T2.BLOG_ID
</select>
</mapper>
|
博客对象依旧不变
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class BlogPO implements Serializable {
private Long id;
private String title;
private String content;
private Long userId;
private List<CommentPO> comments;
}
|
最后加上测试程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class BlogPOTest {
private Configuration configuration;
private SqlSessionFactory sqlSessionFactory;
@Before
public void init() {
SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder();
sqlSessionFactory = sqlSessionFactoryBuilder.build(BlogMapper.class.getResourceAsStream("/mybatis-config.xml"));
configuration = sqlSessionFactory.getConfiguration();
}
@Test
public void testNest(){
BlogMapper blogMapper = sqlSessionFactory.openSession().getMapper(BlogMapper.class);
BlogPO blogPO = blogMapper.nestSelectBlogById(1L);
System.out.println(blogPO);
}
}
|
验证下执行结果是否符合预期:
1
| BlogPO(id=1, title=文章1, content=null, userId=null, comments=[CommentPO{id=1, blogId=null, userId=null, content='你说的对'}, CommentPO{id=2, blogId=null, userId=null, content='写的太好了'}])
|
至此demo已搭建完毕。
一张图了解嵌套映射的原理
.png)
总结一下,结果集在处理结果时,会一行一行的遍历数据。在处理这行数据时,会针对这行数据创建一个rowKey对象,然后调用getRowValue()方法处理这行数据;如果这行数据的某一列的ResultMapping属性是基础属性,直接赋值;而如果是复合属性,就拼装参数递归调用getRowValue()方法,并将结果放入暂存区。
嵌套映射的源码
这次是对结果进行加工,所以所有的逻辑都是在结果集中的,即维护在DefaultResultSetHandler类中。
handleRowValuesForNestedResultMap
这个方法是处理嵌套映射的方法,最主要的是它会遍历每一行的数据。
还要关注rowKey的组成元素
- xml文件路径+resultMap,如org.example.mybatis_reader.mybatis.blog.BlogMapper.BlogNestMap
- 列名,比如ID
- 参数值,比如1
实际上还有其他值,比如图片中这个
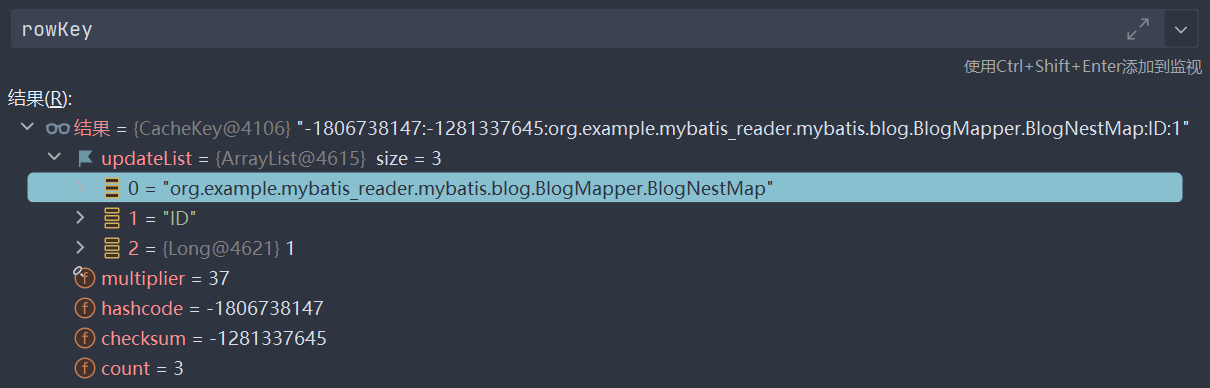
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
private final Map<CacheKey, Object> nestedResultObjects = new HashMap<>();
private void handleRowValuesForNestedResultMap(ResultSetWrapper rsw, ResultMap resultMap,
ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
final DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
ResultSet resultSet = rsw.getResultSet();
skipRows(resultSet, rowBounds);
Object rowValue = previousRowValue;
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
final CacheKey rowKey = createRowKey(discriminatedResultMap, rsw, null);
Object partialObject = nestedResultObjects.get(rowKey);
if (mappedStatement.isResultOrdered()) {
if (partialObject == null && rowValue != null) {
nestedResultObjects.clear();
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject);
} else {
rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject);
if (partialObject == null) {
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
}
if (rowValue != null && mappedStatement.isResultOrdered() && shouldProcessMoreRows(resultContext, rowBounds)) {
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
previousRowValue = null;
} else if (rowValue != null) {
previousRowValue = rowValue;
}
}
|
getRowValue()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, CacheKey combinedKey, String columnPrefix,
Object partialObject) throws SQLException {
final String resultMapId = resultMap.getId();
Object rowValue = partialObject;
if (rowValue != null) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
putAncestor(rowValue, resultMapId);
applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, false);
ancestorObjects.remove(resultMapId);
} else {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
if (shouldApplyAutomaticMappings(resultMap, true)) {
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
putAncestor(rowValue, resultMapId);
foundValues = applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, true)
|| foundValues;
ancestorObjects.remove(resultMapId);
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
if (combinedKey != CacheKey.NULL_CACHE_KEY) {
nestedResultObjects.put(combinedKey, rowValue);
}
}
return rowValue;
}
|
applyNestedResultMappings()
处理嵌套映射逻辑,组装信息,递归调用getRowValue()。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| private boolean applyNestedResultMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject,
String parentPrefix, CacheKey parentRowKey, boolean newObject) {
boolean foundValues = false;
for (ResultMapping resultMapping : resultMap.getPropertyResultMappings()) {
final String nestedResultMapId = resultMapping.getNestedResultMapId();
if (nestedResultMapId != null && resultMapping.getResultSet() == null) {
try {
final String columnPrefix = getColumnPrefix(parentPrefix, resultMapping);
final ResultMap nestedResultMap = getNestedResultMap(rsw.getResultSet(), nestedResultMapId, columnPrefix);
if (resultMapping.getColumnPrefix() == null) {
Object ancestorObject = ancestorObjects.get(nestedResultMapId);
if (ancestorObject != null) {
if (newObject) {
linkObjects(metaObject, resultMapping, ancestorObject);
}
continue;
}
}
final CacheKey rowKey = createRowKey(nestedResultMap, rsw, columnPrefix);
final CacheKey combinedKey = combineKeys(rowKey, parentRowKey);
Object rowValue = nestedResultObjects.get(combinedKey);
boolean knownValue = rowValue != null;
instantiateCollectionPropertyIfAppropriate(resultMapping, metaObject);
if (anyNotNullColumnHasValue(resultMapping, columnPrefix, rsw)) {
rowValue = getRowValue(rsw, nestedResultMap, combinedKey, columnPrefix, rowValue);
if (rowValue != null && !knownValue) {
linkObjects(metaObject, resultMapping, rowValue);
foundValues = true;
}
}
} catch (SQLException e) {
throw new ExecutorException(
"Error getting nested result map values for '" + resultMapping.getProperty() + "'. Cause: " + e, e);
}
}
}
return foundValues;
}
|
流程模拟
我们以Demo中的两行数据为例,来模拟一下整个流程。
第一行
先处理第一行的数据,创建一个博客1的rowKey,假设是A,此时暂存区肯定是没数据的,所以它会先处理基础属性的值,比如TITLE列;然后处理复合属性,恰好这时候复合属性有值:comments。那就要创建评论1信息的rowKey,然后关联上父行的rowKey(A)生成一个联合key,假设为B,然后递归调用getRowValue()处理comments的逻辑,赋完值后将评论1的rowKey(B)放入暂存区。主流程在拿到评论1的对象信息后通过MeatObject赋值给博客对象,最后将A放入暂存区。此时暂存区有A和B两个元素。
第二行
下个循环处理第二条数据,照例创建博客1的rowKey,但是此时暂存区已经有值了,所以它会直接取出第一行的处理结果,然后调用getRowValue()。getRowValue()也不用对博客1的基础属性进行赋值了,直接处理嵌套的comments,并针对第二行的评论2生成rowKey为C,调用getRowValue()生成评论2的对象信息,添加暂存区,最后将第二行的评论对象通过MeatObject赋值给博客对象,整个流程结束。而最终暂存区中有值A、B、C。


.jpg)

%20(%E5%B0%8F).jpg)
.jpg)
%20(%E5%B0%8F).jpg)


