二级缓存的定义 MyBatis的二级缓存是一个全局的缓存,与一级缓存只作用域会话级别不同,它的作用范围是整个应用,二级缓存可以跨线程使用。所以二级缓存有更高的命中率,适合缓存一些修改较少的数据。
开启二级缓存 可以在*mapper.xml中添加一行
开启二级缓存后可以获得以下效果(摘自官网)
映射语句文件中的所有 select 语句的结果将会被缓存。
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存,总共支持以下几种淘汰策略:
LRU – 最近最少使用:移除最长时间不被使用的对象。FIFO – 先进先出:按对象进入缓存的顺序来移除它们。SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对
缓存不会定时进行刷新(也就是说,没有刷新间隔)。
缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
二级缓存整体结构 我们先看一下二级缓存的顶层接口Cache的内容,可以看到只有一些获取以及设置缓存的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public interface Cache { String getId () ; void putObject (Object key, Object value) ; Object getObject (Object key) ; Object removeObject (Object key) ; void clear () ; int getSize () ; default ReadWriteLock getReadWriteLock () { return null ; } }
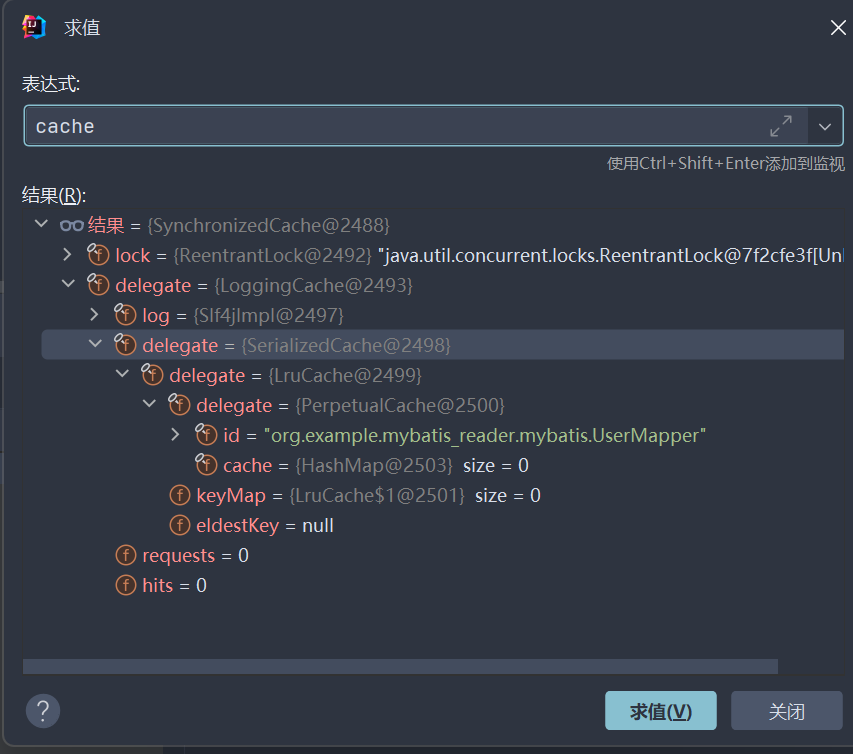
再来一张图了解下整个二级缓存的结构。这里使用的是责任链 + 装饰器模式将整个链路串起来的。
我们写个测试类验证下结构是否和上图一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class SecondCacheTest { private Configuration configuration; @Before public void init () { SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder (); SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(UserMapper.class.getResourceAsStream("/mybatis-config.xml" )); configuration = sqlSessionFactory.getConfiguration(); } @Test public void test1 () { Cache cache = configuration.getCache("org.example.mybatis_reader.mybatis.UserMapper" ); cache.putObject("user" , new UserPO ("张三" )); cache.getObject("user" ); } }
二级缓存的运行机制 以下条件在运行时会影响二级缓存的命中。
会话提交后
SQL语句和参数相同
相同的stamentId
RowBounds相同
还有一些配置也会影响二级缓存的运行
关闭缓存的全局开关,即cacheEnabled设置为false。默认是true。
关闭statement的缓存,即useCache设置为false,举个例子
1 2 3 @Select("SELECT * FROM T_USER WHERE id = #{id}") @Options(useCache = false) UserPO selectUserById (Long id) ;
设置了flushCache = true,这个配置也会将所有缓存都清空掉
1 2 3 @Select("SELECT * FROM T_USER WHERE id = #{id}") @Options(flushCache = Options.FlushCachePolicy.TRUE) UserPO selectUserById1 (Long id) ;
从运行时的参数可以看到,除了第一点,其它三点都是和一级缓存一致的,所以我们只写第一个的用例来测试下。
先写一个会话不提交时的情况,看是否能命中二级缓存
1 2 3 4 5 6 7 8 @Test public void test2 () { sqlSessionFactory.openSession().getMapper(UserMapper.class).selectUserById(1L ); sqlSessionFactory.openSession().getMapper(UserMapper.class).selectUserById(1L ); }
一下是test2()的执行结果,可以看出执行了两次查询,第二次查询并没有命中缓存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [main] DEBUG o.e.m.mybatis.UserMapper - Cache Hit Ratio [org.example.mybatis_reader.mybatis.UserMapper]: 0.0 [main] DEBUG o.a.i.t.jdbc.JdbcTransaction - Opening JDBC Connection [main] DEBUG o.a.i.d.pooled.PooledDataSource - Created connection 908722588. [main] DEBUG o.a.i.t.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@362a019c] [main] DEBUG o.e.m.m.UserMapper.selectUserById - ==> Preparing: SELECT * FROM T_USER WHERE id = ? [main] DEBUG o.e.m.m.UserMapper.selectUserById - ==> Parameters: 1(Long) [main] DEBUG o.e.m.m.UserMapper.selectUserById - <== Total: 1 [main] DEBUG o.e.m.mybatis.UserMapper - Cache Hit Ratio [org.example.mybatis_reader.mybatis.UserMapper]: 0.0 [main] DEBUG o.a.i.t.jdbc.JdbcTransaction - Opening JDBC Connection [main] DEBUG o.a.i.d.pooled.PooledDataSource - Created connection 1177072083. [main] DEBUG o.a.i.t.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@4628b1d3] [main] DEBUG o.e.m.m.UserMapper.selectUserById - ==> Preparing: SELECT * FROM T_USER WHERE id = ? [main] DEBUG o.e.m.m.UserMapper.selectUserById - ==> Parameters: 1(Long) [main] DEBUG o.e.m.m.UserMapper.selectUserById - <== Total: 1
此时我们提交一下会话,看第二个查询能否命中缓存
1 2 3 4 5 6 7 8 9 10 @Test public void test3 () { SqlSession sqlSession = sqlSessionFactory.openSession(); sqlSession.getMapper(UserMapper.class).selectUserById(1L ); sqlSession.commit(); sqlSessionFactory.openSession().getMapper(UserMapper.class).selectUserById(1L ); }
执行结果中显示命中了二级缓存。
1 Cache Hit Ratio [org.example.mybatis_reader.mybatis.UserMapper]: 0.5
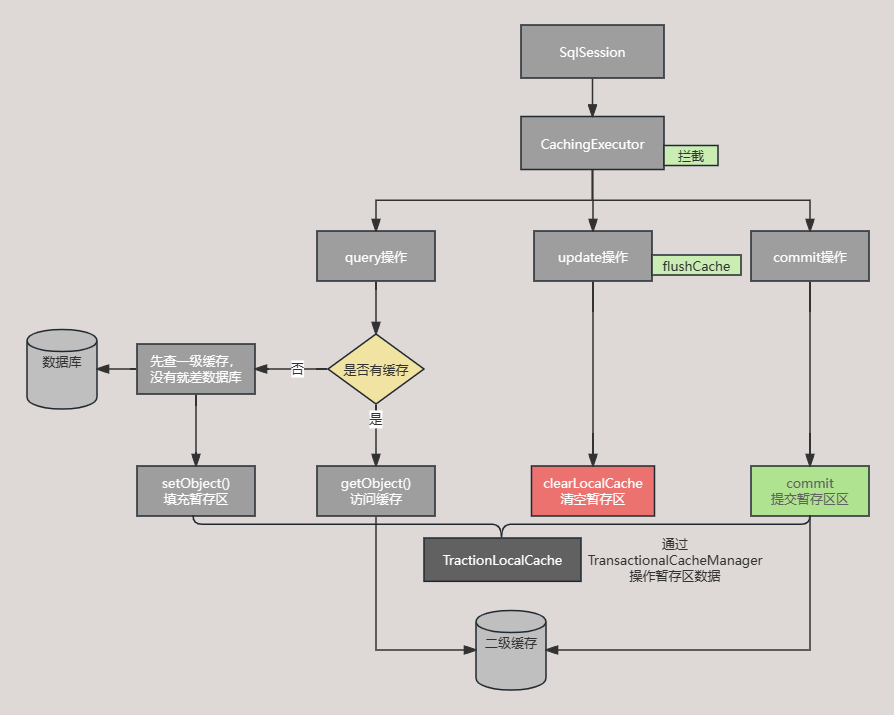
二级缓存源码分析 一张图了解二级缓存整体流程
二级缓存查询流程 整体执行流程是这样:
flowchart LRm
CachingExecutor --> TransactionalCacheManager-->TransactionalCacher-->SynchronizedCacher-->LoggingCacher-->SerializedCacher-->LruCacher-->PerpetualCache
我们依次看下每个类是做了什么
CachingExecutor 通过缓存管理器访问缓存,如果没查到数据就查询一级缓存或数据库,并将查到的数据维护到暂存区中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Override public <E> List<E> query (MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { Cache cache = ms.getCache(); if (cache != null ) { flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null ) { ensureNoOutParams(ms, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null ) { list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); } return list; } } return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
TransactionalCacheManager 事务缓存管理器,里面维护了一个transactionalCaches,主要用于管理和处理事务缓存。
1 2 3 4 5 6 7 8 9 10 private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap <>();public Object getObject (Cache cache, CacheKey key) { return getTransactionalCache(cache).getObject(key); } private TransactionalCache getTransactionalCache (Cache cache) { return MapUtil.computeIfAbsent(transactionalCaches, cache, TransactionalCache::new ); }
TransactionalCache 事务缓存器,用于处理事务中的缓存操作。当事务提交时,TransactionalCache会将事务缓存中的数据提交到二级缓存中。当事务回滚时,TransactionalCache会清除事务缓存中的数据。这样可以确保二级缓存中的数据始终与数据库中的数据保持一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public Object getObject (Object key) { Object object = delegate.getObject(key); if (object == null ) { entriesMissedInCache.add(key); } if (clearOnCommit) { return null ; } return object; }
SynchronizedCacher 线程管理器,用于提供线程安全的缓存操作。在多线程环境中,多个线程可能会同时访问和修改缓存,这可能会导致数据的不一致性。为了解决这个问题,MyBatis使用ReetrantLock关键字来同步缓存操作,确保在任何时候只有一个线程可以访问和修改缓存。
1 2 3 4 5 6 7 8 9 10 11 12 private final ReentrantLock lock = new ReentrantLock ();@Override public Object getObject (Object key) { lock.lock(); try { return delegate.getObject(key); } finally { lock.unlock(); } }
LoggingCacher LoggingCacher也实现了Cache接口,用于提供带有日志记录功能的缓存操作。
在执行查询操作时,会记录缓存命中率、缓存更新次数等。这对于调试和优化缓存非常有用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public Object getObject (Object key) { requests++; final Object value = delegate.getObject(key); if (value != null ) { hits++; } if (log.isDebugEnabled()) { log.debug("Cache Hit Ratio [" + getId() + "]: " + getHitRatio()); } return value; }
SerializedCacher 主要用于对数据的序列化和反序列化。
1 2 3 4 5 6 7 8 9 10 @Override public Object getObject (Object key) { Object object = delegate.getObject(key); return object == null ? null : deserialize((byte []) object); }
LruCacher LRU缓存装饰器,采用LRU算法对数据进行淘汰控制。它的本质是内部维护了一个LinkedHashMap,并重写了其removeEldestEntry()来实现的。
1 2 3 4 5 6 7 8 private Map<Object, Object> keyMap;@Override public Object getObject (Object key) { keyMap.get(key); return delegate.getObject(key); }
PerpetualCache 1 2 3 4 5 6 7 8 private final Map<Object, Object> cache = new HashMap <>();@Override public Object getObject (Object key) { return cache.get(key); }
update操作清空暂存区 update操作并不会真的清理二级缓存,而是先声明一个清除的标记,再清理掉暂存区,最后提交数据库做数据变更(此时数据库还没真正变更,因为事务还未提交),事务提交后清理二级缓存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Override public int update (MappedStatement ms, Object parameterObject) throws SQLException { flushCacheIfRequired(ms); return delegate.update(ms, parameterObject); } private void flushCacheIfRequired (MappedStatement ms) { Cache cache = ms.getCache(); if (cache != null && ms.isFlushCacheRequired()) { tcm.clear(cache); } } @Override public void clear () { clearOnCommit = true ; entriesToAddOnCommit.clear(); }
commit操作提交事务 commit完成后query和update的操作才算生效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Override public void commit (boolean required) throws SQLException { delegate.commit(required); tcm.commit(); } public void commit () { if (clearOnCommit) { delegate.clear(); } flushPendingEntries(); reset(); } private void flushPendingEntries () { for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) { delegate.putObject(entry.getKey(), entry.getValue()); } for (Object entry : entriesMissedInCache) { if (!entriesToAddOnCommit.containsKey(entry)) { delegate.putObject(entry, null ); } } }

.png)

.jpg)

%20(%E5%B0%8F).jpg)

.jpg)


%20(%E5%B0%8F).jpg)